

PotP #16: Older Adults Outperform Young Adults in Identifying Fake News; and MTurk vs Student Sample: Which is better?
PotP #16: Older Adults Outperform Young Adults in Identifying Fake News; and MTurk vs Student Sample: Which is better?
Plus a look at rates of online harassment. Which are about as not-good as you'd expect.
Hello everyone! Happy Wednesday! Welcome to Pulse of the Polis 16.
A couple weeks ago, my wife and I went to go watch the new Spider-Man movie—and let me tell you, it is absolutely worth the hype. To say it was visually stunning is a criminal understatement1; the voice-acting was stellar, and the writing was superb, and the fan-callouts had my patient spouse putting up with me looking like this for most of the flick:

An old Morning Consult poll asked Americans who their favorite Spider-Man is but it, disappointingly, focused only on Peter Parker in the live action renditions. (Sorry gamers, that means Insomniac's Spider-Man wasn't even in the running). But, since it's the multiverse and all, whoever your favorite Spider-Man is, you're sure to find them somewhere. And if you're interested in Spider-Man and identity (though not necessarily just his secret identity), you should check out this super interesting Conversation article looking at the ethnoracial identities of two Spider-Men that feature prominently in the film.
Alright! Let's swing into today's reviews!
I’ve got three projects for you today:
Today’s accidental theme: "The Internet—sometimes it ain’t as great as we’d hope!”
A YouGov poll that looks at how well (read: poorly) people identify fake news headlines.
A study commissioned by the Anti-Defamation League looking at levels of online harassment.
Comparing Amazon’s MTurk and a Sona Student Sample: A Test of Data Quality Using Attention and Manipulation Checks | Survey Practice
A huge amount of experimental psychology has been built off the back of university undergraduates. However, the world is not solely comprised of university students (which, looking back on how clean my and my friends’ dorms were, thank God). As a consequence, many researchers turn to online respondent pools to have “higher quality” or “more diverse” samples to test their theories. This article in Survey Practice by Yani Zhao and Sherice Gearhart investigates whether, ya know, said online pools actually deliver on these promises (at least in one empirical case study). Using multiple measures of “response quality” (filter questions, manipulation checks, attention checks, and response speed), the authors compared a student sample recruited on Sona (a common platform used at universities to recruit in-school participants for experiments in exchange for course credit) and Amazon MTurk, perhaps the most notorious online participant pool. The sample was female users of Instagram. They found that the MTurk sample was higher quality in some measures (screeners and attention check) but that the University sample was better in others (context-specific/context-transcendent manipulation checks). The samples completed the instrument at roughly equal average speeds. In this case, the University sample was more ethnoracially diverse. The authors thus conclude that the choice of sample ought to be guided by the whatever the population of interest is in the research question.
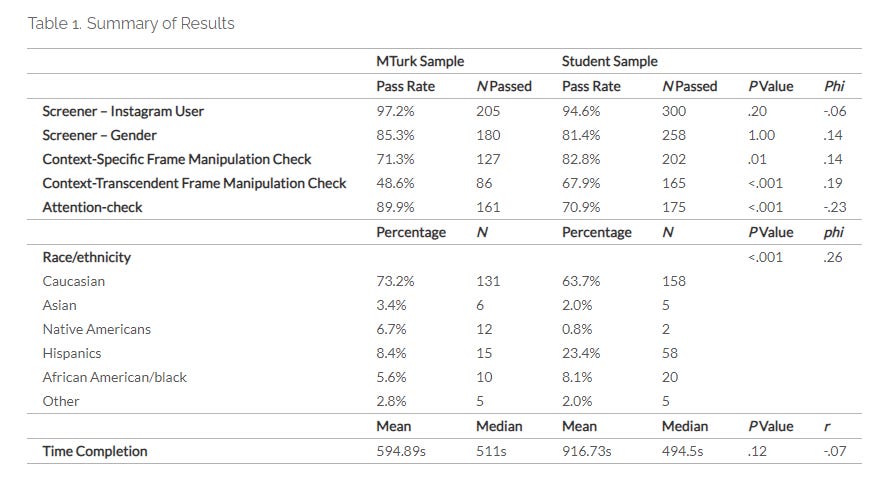
I love the impetus for this article and I think it offers a really important point. Scholars are often pushed to web marketplaces to either address/preempt charges that their sample is too WEIRD. Psychology undergrads are the lab mice of a large swath of social science research2. Many of these researchers don’t have huge budgets, so they’ll try to navigate these marketplaces because they offer cheap sample—and often do so alone. But these platforms are not intrinsically better! Their samples also have their own skews and idiosyncrasies. If you don’t know how to avoid them you can find yourself with even crappier data than the critics imagine the student samples to be! To quote Justin Sulik when discussing a different paper than used MTurk: “Why in the year of our lord 2023 is anyone still rawdogging MTurk?”
Another thing that I like about this study is that it doesn’t flinch at the contradictions found from different kinds of quality checks: One was better for MTurk, another for the students. So which is better? You’re never going to believe what I’m going to say but…it depends! Attention checks, as best as possible, should reflect the measure of interest and the stimulus! If you’re testing whether a video ad elicits a particular effect, I’d argue that a speeder check often suffices; people tune ads out anyways and forcing close attention may inflate your estimated treatment effect. If you need people to read a detailed vignette, maybe making sure that they will at least answer “somewhat agree” when you explicitly say to do so wouldn’t be the worst idea. I like how this paper plays with this by just matter-of-factly saying “this is better” as if the previous results hadn’t existed. Unironically brilliant.
That said, while I think that the study is a good and has a really important takeaway, I do think that some of these findings are likely contextual—or could be easily remedied. For example, the fact that the student sample was more ethnoracially diverse. There are lots of diverse schools out there, but there are also very White schools out there; depending on the institution. It’s possible that MTurk would’ve been more diverse had the Sona sample been sourced from a different location. (The authors, to their credit, note that this may be due to the fact that the student body was fielded at a federally designated Hispanic Servicing Institution). Even if it wasn’t, it’s relatively easy to employ quotas such that you can get a more diverse sample if that’s your goal. And every part of the project (especially fielding) needs to be aligned with the projects’ goals. It also makes sense that the MTurk respondents were more likely to fail the kinds of attention checks that require deeper thought: The students were getting a quarter class credit; the Turkers got $1.50! The fact that students on average have a higher need for cognition aside, one of those things is worth a lot more than the other!
But the point of this paper, I feel, remains: MTurk and its ilk will not necessarily give you a “better” sample than university students on its own. If you want to use these platforms to provide some benefit that other samples don’t have, you have to make sure your study is set up to make them arise!
How well can Americans distinguish real news headlines from fake ones? | YouGov
Here’s my entry for understatement of the year: Fake news and misinformation is a bit of a problem right now. In the Internet age, we find ourselves in a deluge of information—a lot of it intentionally false or misleading. Linley Sanders, writing for YouGov, puts the truth-detection abilities of approximately 1,500 US adults to the test. Using a combination of 10 true and 10 false headlines (taken from the Misinformation Susceptibility Test), this poll finds that about 50% of respondents misclassified 7 or more headlines. Some true statements were correctly classified by the vast majority of respondents (e.g., “Republicans Divided in Views of Trump’s Conduct, Democrats are Broadly Critical”, 80%); others were trickier (“Hyatt will remove small bottles from hotel bathrooms”, 64%). Similarly, some false statements were overwhelmingly identified as such (“Ebola virus caused by US nuclear weapons testing, new study says”, 81%) while others were more convincing (“New Study: Left-Wingers are more likely to lie to get a higher salary” 54%). Contrary to prevailing narratives, older adults tended to have substantially higher scores than those 18-29—and those who were online recreationally for more than 4 hours a day were more inaccurate. Those who get their news sources from sources such as Snapchat, WhatsApp, and TikTok were overwhelmingly more likely to score fewer than 10 correct than those who read more traditional news outlets.
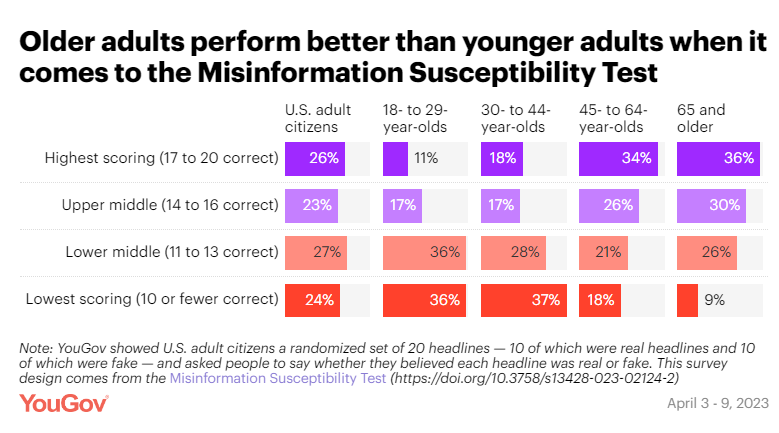
There’s a lot to unpack here. Like “I know it’s been a year since we moved in, but I just haven’t gotten around to putting the photos up on the walls yet” levels of stuff to unpack.
Some of it was surprising: Given that the report also found that Republicans were generally less accurate than Democrats and Independents, I would’ve bet that age would’ve been a big confounding factor with older adults faring worse overall. (Especially given the evidence that older adults are more likely to be exposed to fake news.) That said, this isn’t the first time I’ve seen results where the youngin’s didn’t exactly school the old folks. More work needs to be done here (as always), but here’s my very tentative hypothesis: Maybe older folks, by virtue of having more experience with how legitimate information is presented, are more accurate at discriminating things by headline alone. However, if they’re also more inclined to traffic spaces where more (and more sophisticated) forms of fake news are more prevalent, their higher rate of sharing fake news may come from higher exposure. That is to say: Their batting average may be better than younger folks, but because they’re “at bat” far more often, they’ll get more strikes overall. Just a hypothesis, I’d love to see it get researched though!
I’m also not entirely surprised that we start to see a diminishing return for time spent online with accuracy. At some point, a relationship stops being a cause and starts being a symptom. People who are so invested in the internet that they’re spending over 4 hours of recreation time a day on it are probably not spending that time binging stories from NPR and the Economist. And when you get to people spending a mind-boggling nine hours daily online, you’re talking about folks who have quite likely passed the conspiracy event horizon. Similarly, I’m also not surprised that social media, where engagement is rewarded more immediately and visibly than accuracy, tends to not prepare people to discern news headlines correctly. Have you seen the crap people peddle as facts on TikTok?! Colbert’s “Truthiness”3 reigns supreme there—as well as on the ironically named Truth Social.
So, all in all, I think this is an incredibly valuable and thought provoking project. A good bit of proof that the vast majority of us are not quite as good at identifying misinformation on sight as we’d probably like to believe.
I do have a couple of methodological suggestions for works that build off of this. First, though the vast majority of people only read the headline, it might be good to see how well people identify fake news if each headline was accompanied by a 1-2 sentence “summary” of the article that the headline accompanies. A lot of social media cards and search engines will also carry a subtitle and/or article snidbit, so this might better mimic what people will see in those sorts of contexts. Second, and relatedly, I think it might be good to get a measure of people’s confidence that the story is true/false, not just a binary judgment. For example, I think I and others would probably get some of these less informationally-dense “correct” headlines wrong (“Hyatt will remove small bottles”) because they’re less confident in the story. There’s a lack of information in the headline that coheres with my mental models of the world4. Sure, it seems plausible that Hyatt could do that—but I’ve seen more banal shit get made up for no other reason than lulz. It’d be a coinflip to me whether I’d say it’s true or not because I’m just not that confident due to the lack of accompanying information. Plus, and I’ve said this a million times, you can always discretize a continuous variable5, but you oft can’t make a discrete variable continuous.
I happen to be reading a book by a prominent scholar of misinformation right now—one who is being directly responded to by the paper that inspired this YouGov post. So I’ll hopefully have more thoughts about that when I get to it next week!
Online Hate and Harassment: The American Experience 2023 | Anti-Defamation League
Ok, I’m going to take another stab at understatement of the year: Online harassment is not great. The Internet can at once be a magical bazaar where you can plumb the depths of man’s knowledge, be endlessly entertained by several lifetimes of content—but it can also be a hive of scum and villainy. This survey conducted by YouGov on behalf of the Anti-Defamation League (ADL) shows that online harassment is both prevalent and exhibiting some disconcerting upward trends. 52% of Americans report having ever been harassed online, with about a third saying that they were harassed in the last year. Men report slightly higher degrees of online harassment than women (35% vs 31%); 38% of Black respondents report online harassment in the last 12 months compared to 34% of White respondents, 30% of Hispanic/Latino respondents, and 26% of Asian Respondents. 44% of Jewish respondents reported online harassment and 51% of Transgender respondents did so—similar to the 47% of people identifying as LGBTQ in general. In all cases, if respondents identified experiencing online harassment, it was more likely to be “severe” harassment than otherwise.

If you look at the trends over time, for both topline levels and for White Americans specifically, you’ll notice a weird V pattern in the data. My first instinct was that it was a methodological artifact; a change in how sample is collected could very well cause patterns like these. However, looking back at prior years’ reports, it seems that they used YouGov for all three of the years plotted6. But what caught my eye, looking at the methodology, was that they oversampled 500 Jewish respondents and (at least) 200 Black, Hispanic, Asian, Muslim, and LGBTQ Americans apiece. Keeping it at just those numbers, that means that they would’ve gotten about 800 Non-Hispanic White Respondents. (This year, the number would’ve been closer to 600 or fewer in this wave since they also oversampled Transgender Americans).
On the one hand, this oversampling is good because, often, people will try to analyze demographic cuts of these groups when their total sub-group responses number in the single-digits. Here, subgroup analyses are much more feasible. However, in a reversal of the normal turn of events, this means that the Non-Hispanic White respondents had to have been pretty substantially upweighted since their raw sample size was much lower than their overall percentage of the US population. Some of what we could be seeing here could just be the increased variation that would come with smaller samples.
Even if that is the case though, all of the subgroups except Asian Americans seem to be reporting higher incidences of harassment compared to two years ago, too. Again, with the small sample size, I’d prefer more observations before establishing a trend. But any trend (or proto-trend) that isn’t down (especially given its prevalence) means that there’s work to be done.
I’m realizing upon my final readthrough that “understatement” is a prominent trope in today’s issue.
Which, to me, doesn’t mean that they should be dismissed out of hand. But, like with lab mice, the findings need to not be oversold and be properly contextualized.
Truth you feel in your gut, rather than having to look it up in those stuffy pagey things called books.
Yes, I’m fully aware that’s how we get hoodwinked with fake news—but true things are broadly coherent too!
Though you really should think about whether it’s the right call.
YouGov is an exclusively online shop and their core methodology has been the same for a while now.